


Opportunities in Data Analytics
Weekly updates on the innovation economy.

Background
“Big Data” and data analytics have become hot subjects in recent years, with companies such as Snowflake, Google Cloud, Palantir, and Databricks all grabbing major headlines. Through rising data availability and collection, companies all over the world are acquiring and analyzing data in order to gain a competitive advantage. In 2020 alone, 64.2 ZB of data was either created or replicated (1), which is the equivalent of the storage capacity of 501.5 billion new iPhone 13s.

Today, we will review the data market from a top-down perspective, discuss key industry trends, and highlight a few areas of innovation in the space that have been trending upwards for the better part of the last decade.
The visual representation below highlights Google Trend searches for “Data Analytics” in the United States, as of September 22, 2021:

Based on recent headlines alone, one might think that the rise of big data, artificial intelligence, and machine learning are a recent trend. However, the sequential trends of big data, AI and ML, and automation are really part of a larger secular trend, each enabling the next.
While some may believe that this is a short-term fad, enabled by an accelerated digital adoption to accommodate a remote world, we believe that this trend remains in the early innings of what will be one of the most dramatic shifts in the way that the world operates. To remain competitive, each and every company must not only become a software-enabled business but a data-enabled business. After all, knowledge is power.
Let’s start with some fundamentals:
The exponential growth in both structured datasets and unstructured data enables companies to observe their data, deliver better consumer experiences, develop high-growth revenue models, and integrate data science to create platform technology companies.
The combination of network effects, asymmetric information, increasing returns to scale, and technological advantages have enabled many internet-scale companies and digital businesses to experience a “winner take most” market environment in specific categories. The accumulation and analysis of data enable these traits.
Positive network effects imply that as a company gains more customers, all of the previous customers also benefit via a better product or service, which creates an accumulating competitive advantage with increasing marginal utility with greater size, scope, and scale.
The Data Science Hierarchy of Needs
Monica Rogati’s blog post outlines the data industry's hierarchy of needs. Here, we can see the natural progression from the base of the pyramid (data collection) to the tip of the pyramid (learning, optimization, and programmatic decision-making).

Source: https://hackernoon.com/the-ai-hierarchy-of-needs-18f111fcc007
Using the “Data Science Hierarchy of Needs” as a framework, we can start to fill in the blanks of each of the levels, and align timelines and product roadmaps of leading companies in the industry.
One of the key trends that has propelled the surge of data-driven companies actually has to do with the most fundamental level of the hierarchy pyramid: data collection. Until recently, large amounts of data were not processed efficiently - either it required large technical teams or it was otherwise very cost-prohibitive. Today, cloud warehouses and “lakehouses” such as Snowflake, Databricks, Google BigQuery, and Amazon’s S3 bucket and Redshift, all make data storage and processing more efficient and massively increase the potential of new solutions and a means of market access to new entrants. This has widespread benefits for the rest of the industry, including:
Increased expansion of total addressable markets - as many data service providers offer consumption-based pricing, new entrants can access the same high-quality products as large enterprises at a lower starting cost. This lowers the barrier to entry for startups, which now become new customers for the data service providers, and in turn the startups can serve customers and grow their own addressable markets, which have beneficial first-order and second-order effects.
Enablement of new tools and services - with increased access and greater market efficiency, new suites of tools become available to everyone. This has also given rise to the modern data stack (see illustrations below).

Increased value-to-time for market participants - since businesses can now outsource the storage and processing of data more efficiently, they can reallocate time and resources to higher-value projects such as serving customers, engaging in mutually beneficial partnerships, R&D efforts, and scaling their businesses.
So, now that the most fundamental layer of data science has unlocked massive potential, and companies at all levels of the data hierarchy are benefiting, where is the innovation happening?

Innovation in Data Infrastructure
There is no shortage of startups coming to market in the data infrastructure space. In the first half of 2021 alone, roughly $31 billion was invested into AI-focused startups, with 42 artificial intelligence companies reaching a billion-dollar-plus valuation (9). With this flood of capital entering markets, we would like to highlight a few very exciting areas of innovation in the data infrastructure market:
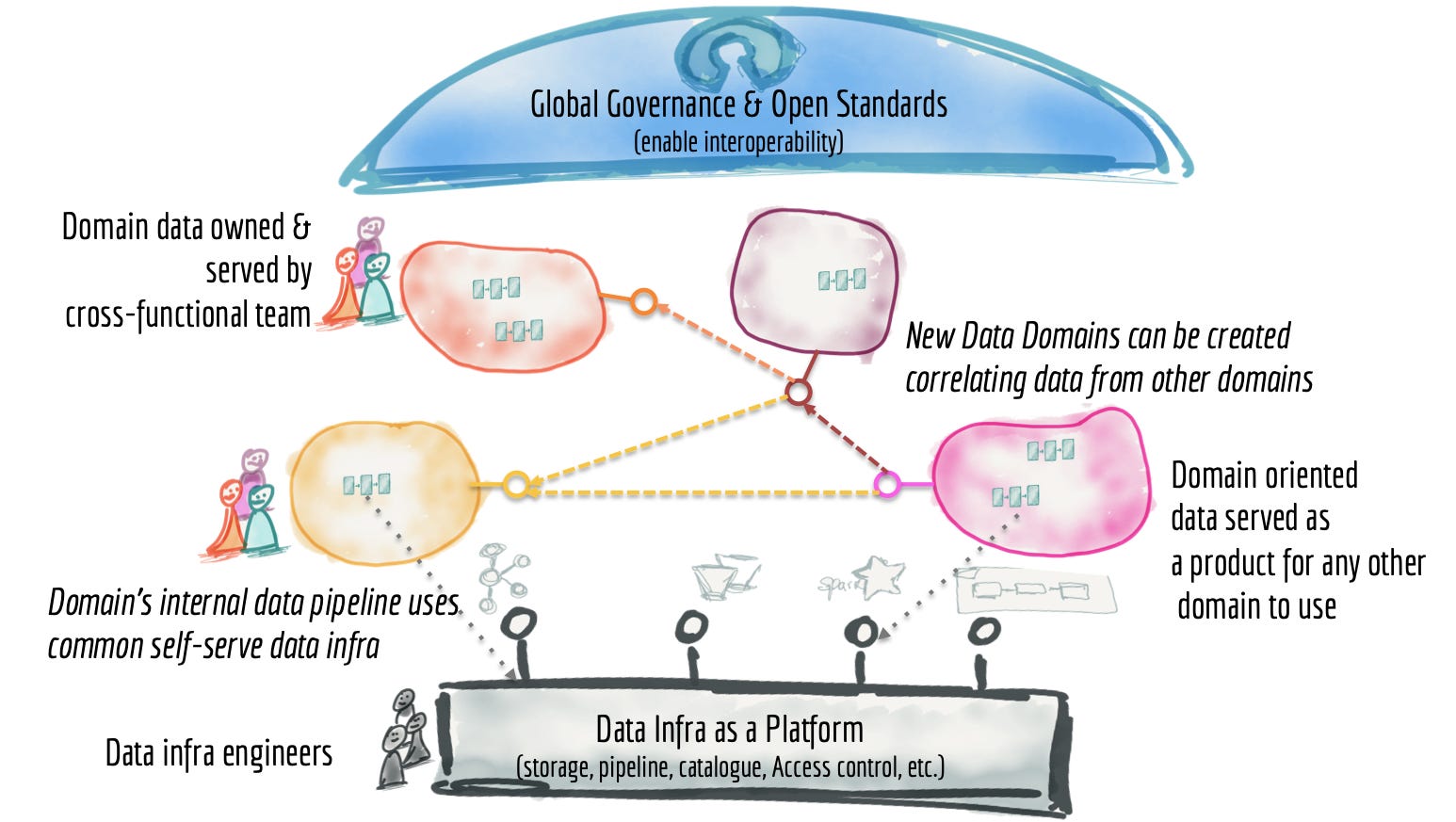
Data Mesh: The data mesh is more of an organizational concept that aims to help data teams operate more efficiently. As opposed to the traditional, centralized method of a single data team serving several business cases, a data mesh decentralizes the organization, with multiple data teams each specializing in their own domain and provide data-as-a-product to others in the organization (see diagram below from https://martinfowler.com/articles/data-monolith-to-mesh.html).
Data Observability: Data observability is the process of eliminating data “downtime” through the automation of triaging, alerts, and monitoring. This is further segmented into a) data lineage, and b) data quality. Each of these segments has seen an acceleration in new market entrants. Data observability is an increasingly competitive industry, and pure-play category leaders in data observability include Datadog, Sumo Logic, Splunk, Dynatrace, and New Relic.
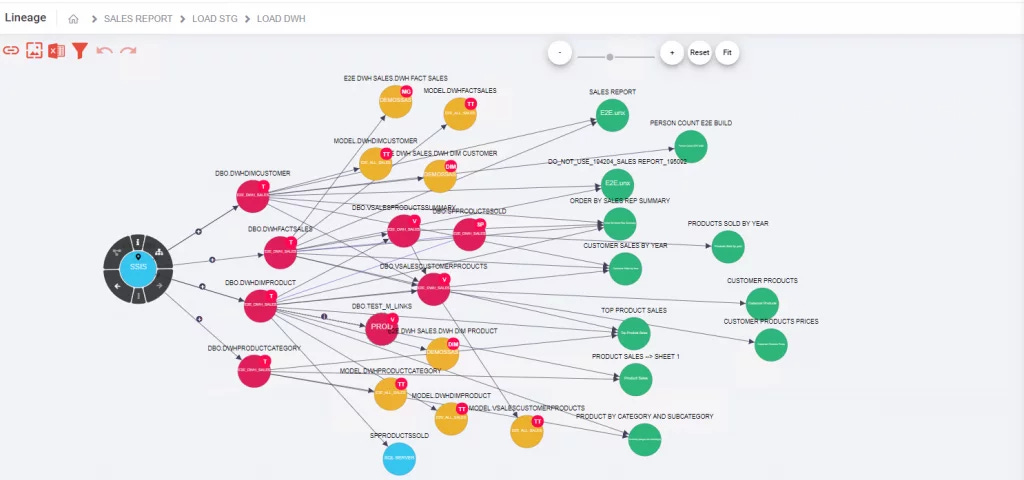
Data Lineage: We can define data lineage as the data’s life cycle or the full data journey. This life cycle includes: where the data originates, how it has gotten from point A to point B, where it exists today, and how the data can provide a source of actionable insight or inference.
Throughout data’s journey, it interacts with several different types of information, is transformed, and then utilized in additional reports. Instead of manually compiling all of the data sources, companies can utilize an automated data lineage tool. This allows data teams to receive relevant information from all of their different data sources, instantly and updated in real-time. Here’s a snapshot of what that looks like:
Data Quality: The definition of data quality is self-explanatory. However, in practice, different teams of software developers use different approaches across different data sets, and the definition of “quality” data can become more opaque. Teams can either set explicit rules for declaring what a “quality” dataset looks like. Or, AI and ML models can be used to automate that process for the team. As the output of any predictive or historical analytics is heavily reliant on the quality of data, solving the problem of data quality is a rapidly growing market.
Real-Time Analytics: Real-time analytics is the concept of collecting data and, you guessed it, analyzing it in real-time. Also called “streaming,” this process has been around for years, but is now starting to gain significant traction with the proliferation of data warehouses and data lakes.
Previously, analytics was processed in batches. A common analogy for comparing the two is setting aside an hour to respond to all of your emails (batching) versus texting someone back and forth immediately (real-time). This provides key advantages for businesses by receiving immediate feedback on the data collected and can be acted upon right away.
Comparisons Across Data Companies
In both public and private markets, data and AI/ML companies continue to command high growth rates and margins. As a result, investors have rewarded these companies with higher price multiple expansion and higher equity valuations in financial markets. Here’s a brief overview of the key players in the modern data stack:

Source: (8)
To conclude our review of Opportunities in Data Analytics, let’s quickly look at public equity price multiples and metrics for a select group of companies.

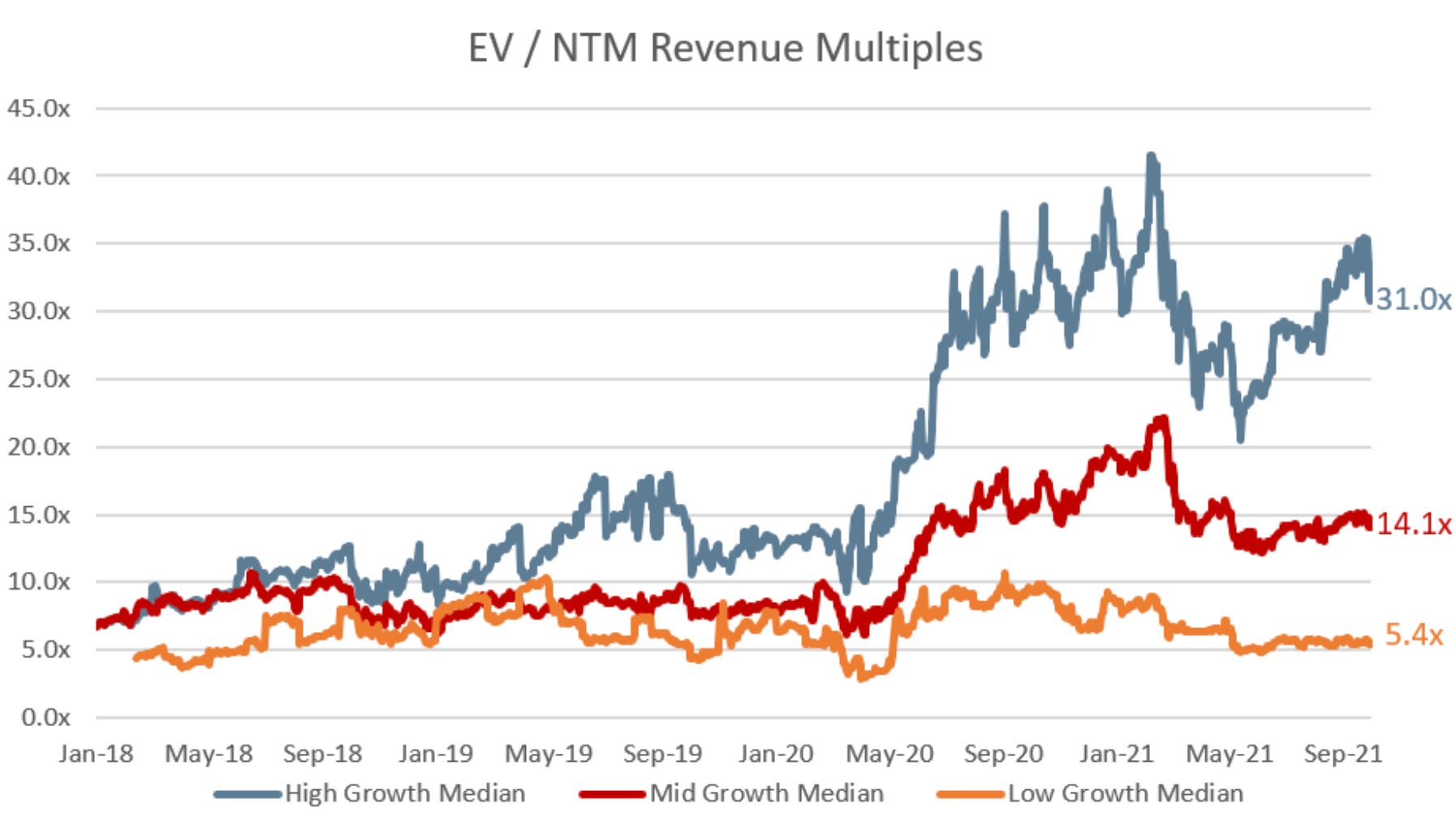
While the median for high-growth companies (revenue growth rates of >30% per year) was 31.0x EV/ NTM revenue, Snowflake was trading at 59.2x EV/NTM revenue, SentinelOne at 51.0x, Datadog at 39x, and Confluent at 36.5x, as of October 1, 2021. For reference, EV/NTM revenue is the ratio of enterprise value dividend by a company’s estimated revenue over the next twelve months.
This reaffirms that being a category leader in a market with a rapidly growing TAM (total addressable market) can prove to be a winning strategy over the long term. This is especially the case for those who act as large-scale enablers within the market.
For additional insights and opportunities in the data analytics industry, Drawing Capital recently presented a webinar on this topic, which can be found at this link: https://ibkrwebinars.com/webinars/opportunities-in-data-analytics/

References:
“Data Creation and Replication Will Grow at a Faster Rate than Installed Storage Capacity, According to the IDC Global DataSphere and StorageSphere Forecasts.” https://www.idc.com/getdoc.jsp?containerId=prUS47560321. Accessed 6 Oct. 2021.
“Red Hot: The 2021 Machine Learning, AI and Data (MAD) Landscape.” https://mattturck.com/data2021/. Accessed 6 Oct. 2021.
“Resilience and Vibrancy: The 2020 Data & AI Landscape.” https://mattturck.com/data2020/. Accessed 6 Oct. 2021.
“How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh.” https://martinfowler.com/articles/data-monolith-to-mesh.html. Accessed 6 Oct. 2021.
“The AI Hierarchy of Needs.” https://hackernoon.com/the-ai-hierarchy-of-needs-18f111fcc007. Accessed 6 Oct. 2021.
“What is Data Lineage?” https://www.octopai.com/what-is-data-lineage/. Accessed 6 Oct. 2021.

8. Zhou, Jimmy. “The Dangers of Palantir (PLTR) in 2021.” Insights on SaaS Businesses and Markets, Public Comps. 7 Oct. 2021.
9. “CB Insights Q2_21 State of Venture Report”. https://www.freewritings.law/wp-content/uploads/sites/24/2021/07/CB-Insights-Q2_21-State-of-Venture-Report.pdf. Accessed 7 Oct. 2021.
This letter is not an offer to sell securities of any investment fund or a solicitation of offers to buy any such securities. An investment in any strategy, including the strategy described herein, involves a high degree of risk. Past performance of these strategies is not necessarily indicative of future results. There is the possibility of loss and all investment involves risk including the loss of principal.
Any projections, forecasts and estimates contained in this document are necessarily speculative in nature and are based upon certain assumptions. In addition, matters they describe are subject to known (and unknown) risks, uncertainties and other unpredictable factors, many of which are beyond Drawing Capital’s control. No representations or warranties are made as to the accuracy of such forward-looking statements. It can be expected that some or all of such forward-looking assumptions will not materialize or will vary significantly from actual results. Drawing Capital has no obligation to update, modify or amend this letter or to otherwise notify a reader thereof in the event that any matter stated herein, or any opinion, projection, forecast or estimate set forth herein, changes or subsequently becomes inaccurate.
This letter may not be reproduced in whole or in part without the express consent of Drawing Capital Group, LLC (“Drawing Capital”). The information in this letter was prepared by Drawing Capital and is believed by the Drawing Capital to be reliable and has been obtained from sources believed to be reliable. Drawing Capital makes no representation as to the accuracy or completeness of such information. Opinions, estimates and projections in this letter constitute the current judgment of Drawing Capital and are subject to change without notice.